
A cautionary tale on biological truths
or how your textbook lies

Your biology textbook lies.

By implication.
The cell you learned so much about in college and grad school doesn’t exist.
Let me tell you a story and we’ll get back to this.
Biological Truth Benchmarking
In the early days of Turbine, our model was a hand-wired signaling graph, painstakingly tuned to reproduce textbook behavior. It was fragile and at best passable in terms of predictive performance, but people using the simulations knew exactly what was going on inside.
Then we started using AI to do the wiring.
We shattered previous performance ceilings, but also mechanistic expectations along with them. When biologists looked into the pathway activation patterns, they were alarmed. The virtual cell was clearly doing the wrong thing in response to drugs.
It was not a surprising outcome - from the AI’s perspective the whole protein graph was merely a bunch of tunable parameters to fit a million data points with. And there are a lot of ways to fit with a million data points with tens of thousands of parameters.
OK, so we need a way to guide the AI. But how?
We started writing a set of textbook rules.
Suppose protein A and protein B are both required to activate protein C, and C has no other inputs. Any wiring where C activates when only A or only B is present must be prohibited.
We crafted more than a thousand such rules and called them Biological Truth Benchmarks, or BTBs for short. Here are a few examples.

As you see, we quickly had to realize that real protein interactions are much messier. Pathways have interactions, so many ifs and yes-buts that rules like these cannot fully capture (the “biological context”).
Still, it’s better than nothing, right?
So we started building these rules into the loss function.
But given the lot of ifs, how strongly should the model obey them? We didn’t know the exact cell lines in which these rules were originally established. Even if we did, they were measured in only a handful of cellular contexts, making them a drop in the ocean compared to other training data.
So we decided that each rule should hold in the majority of cells.
For an ML engineer, this is a horrifying criterion. Optimization can no longer happen independently per sample. The order of samples starts to matter. Sweat and tears were had. But eventually a working setup emerged.
And the results were underwhelming.
Training was much harder, performance didn’t improve, and many horrible mechanistic quirks remained.
There is no general cell
Investigation revealed that in clear contrast to what we wanted, performance and BTB scores were disconnected. You can have excellent predictive performance with terrible BTB scores (which is where we started) but also excellent BTB scores with terrible predictive performance.
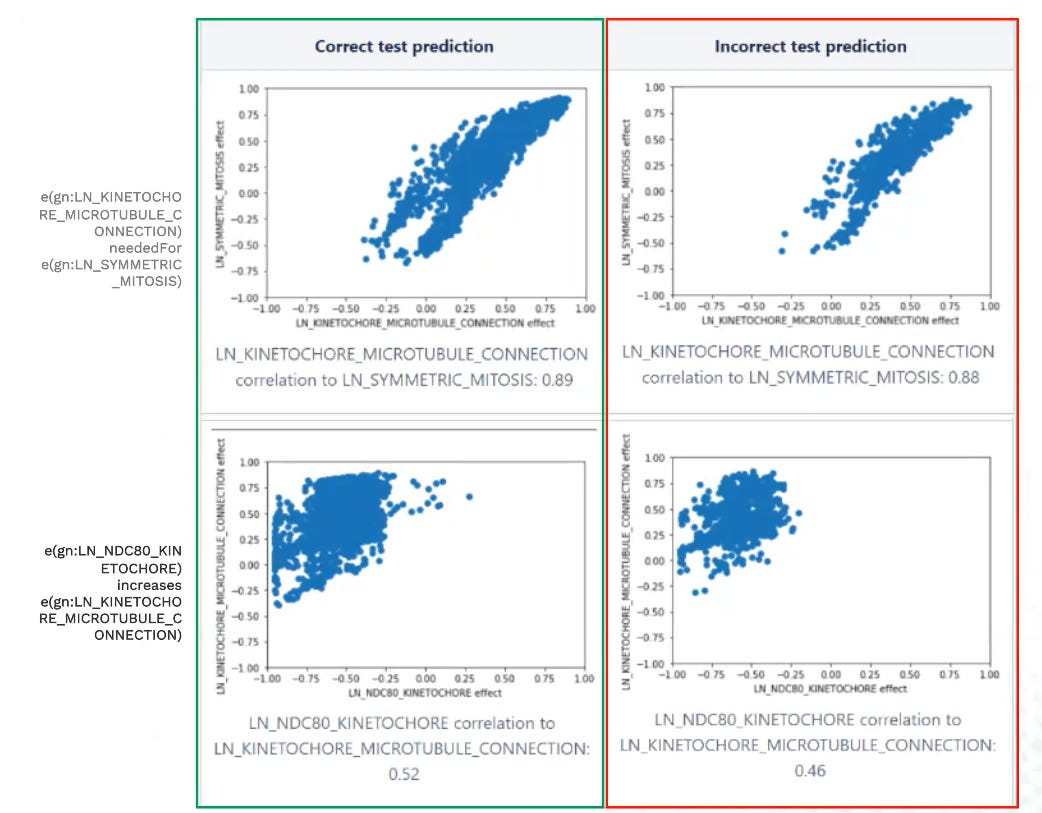
Which defeats the whole purpose.
Worse, there was a trade-off in trainings between BTB and viability performance.
Some argued that performance didn’t matter if the mechanism is more correct. But if the performance degrades, the model generalizes less. And if it generalizes less, it is — by definition — capturing less of cells’ internal workings.
This is deeply counterintuitive — if the model obeys more of the scientifically established rules, how can it generalize worse?
Because scientific truths are themselves overgeneralizations of the underlying data.
Science is built by humans, for humans. It’s an explicit job of science to compress the messy, complicated reality into understandable decision rules. Each rule, individually, would be a sound decision in the context it was derived.
It blows up when you start combining these rules.
Our mistake was saying that each rule should work in the majority of the cells without precisely defining said majority.
Because if you just optimize any majority (and the rule indeed applies to roughly a majority), you’ll get, on average, half the cell lines wrong with each rule.
With 1000 rules the chance of getting any appreciable amount cell lines right for most rules is, for most intents and purposes, zero.
So by training to BTBs, we were explicitly teaching the wrong idea to the machine. The idea of the general cell described in the textbooks to which all rules apply equally.
But that general cell doesn’t exist. There is no single cell in which all these rules are simultaneously true. Some rules will be observable in a certain type of cell, but not others — there will always be some cell-specific activity that interferes with some rules.
The pattern of which rules apply where is precisely what distinguishes cell types. It is the keystone of predictive performance.
Now what?
If you want mechanistic correctness, you need mechanistic ground truth.
Post-treatment RNASeq, protein phosphorylation assays — something that gives you an additional trace inside the cell besides your endpoint.
The implication is unsettling, but also fascinating: real biology is much more complex than what can be contained by textbooks — most of that world is still waiting to be discovered.
Does this mean we should fire the experts and just collect more data?
Of course not.
First, you need the experts to match the right ML metric to the downstream application — Does a better score on your chosen metric give results they’re happier using? If not, you are optimizing the wrong objective.
Second, humans are horrible detecting if a fact is true — that’s what rigorous metrics are for. But we’re remarkable in detecting when something feels off, much better than any predefined ML metric.
So that’s the workflow I’m trying to drive in-house:
When experts detect a smell, capture it in data.
Make sure the metric is sensitive to those new examples.
Optimize against that expanded ground truth and iterate if needed.
And assume as little as possible.
As we got closer to correctly simulating biology, one textbook assumption after another fell apart. First the fixed-form equations, then the fixed activity patterns, and finally even the graph abstraction itself.
But that’s a story for another time.
Thanks for all that work 3 years ago, Laszlo Mero, Csilla Hegedus, Dora Kallai and Robert Sipos (and the reviews for Imre Gaspar and Balint Paholcsek)!