
The best experiment doesn't exist
as shown by an analysis of DepMap data

Important service announcement: we’ve just launched a new virtual-cell research site at research.turbine.ai featuring a curated set of research problems where we can support collaborations with data, feedback and validation.
What is the effect of knocking out the EGFR gene in HCT-116 cells?
Does this question even have a clear answer?
We’re generally very interested in experimental reproducibility, as it is a cornerstone of good AI in biology.
It's well known that reproducing biology within the same lab is much easier than reproducing it across labs. But we generally expected stronger signals to reproduce more reliably across labs.
Diving Dep(Map)
That expectation started to change when we took a deeper look at the Dependency Map CRISPR data.
Most of the data comes from two major contributors: Broad and Sanger. Broad uses the Avana CRISPR guide library, while Sanger uses KY.
At first glance, the agreement looks respectable, r=0.73.
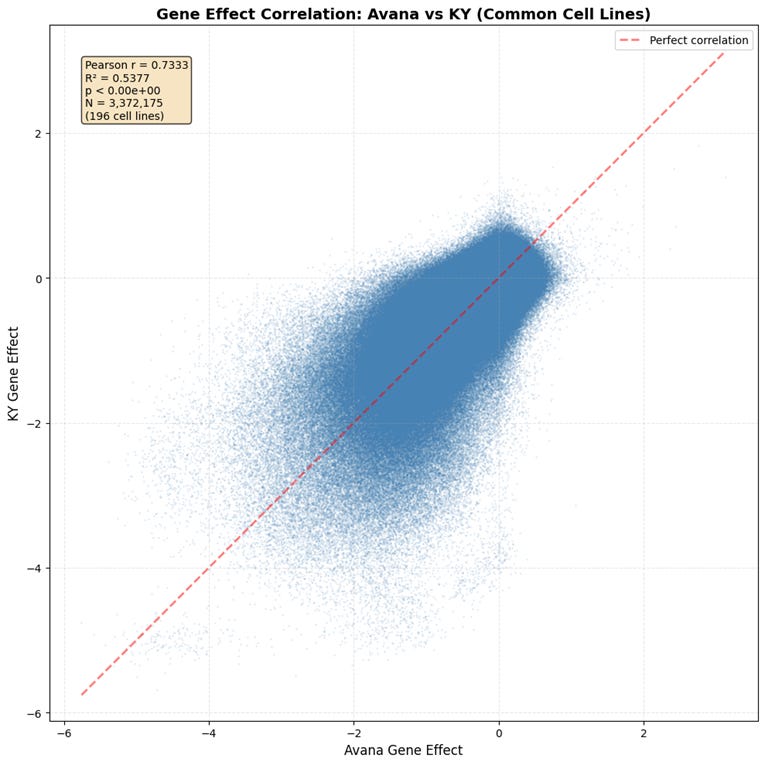
A veteran bioinformatician might raise an eyebrow at the spread in the high-effect region, but overall the plot looks reasonable.
However, when we start to filter for significant gene dependencies, the correlation craters. (r=0.347).
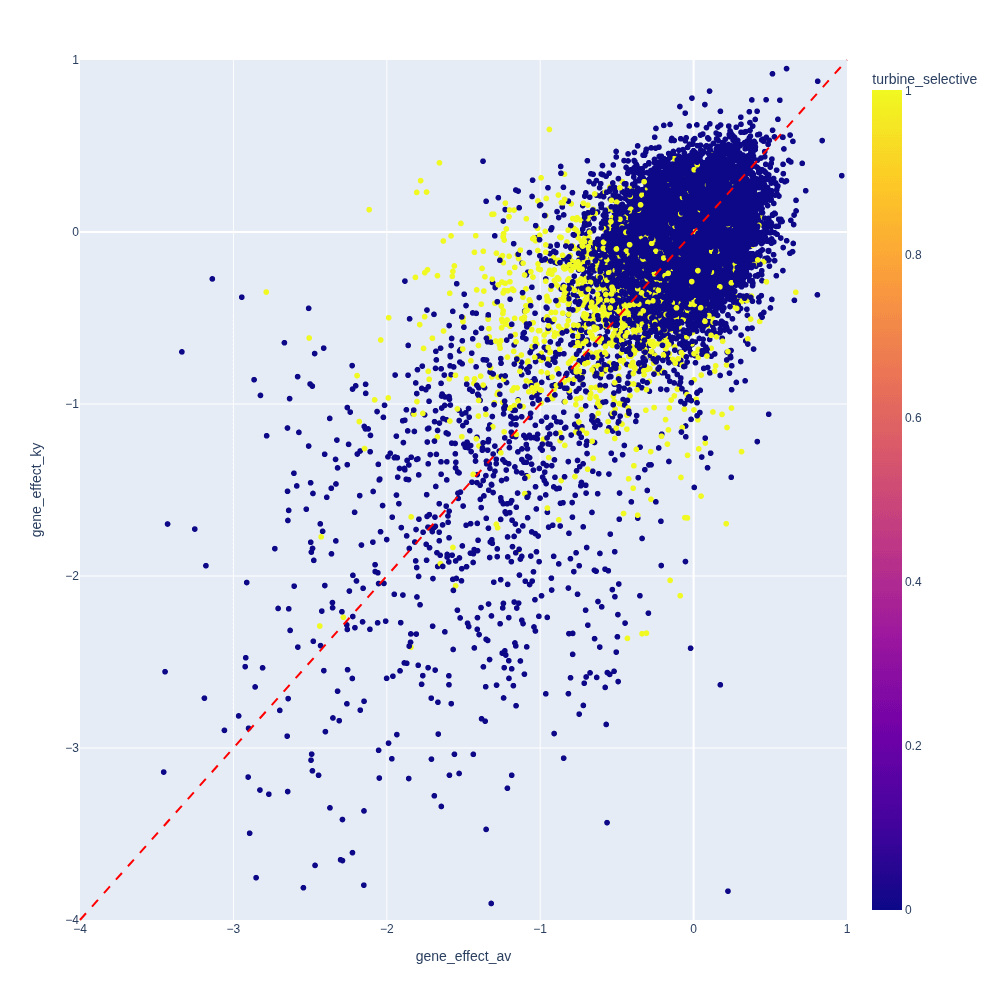
That’s concerning. But could it simply be natural variability?
This is what the Broad dataset’s internal replicates look like:
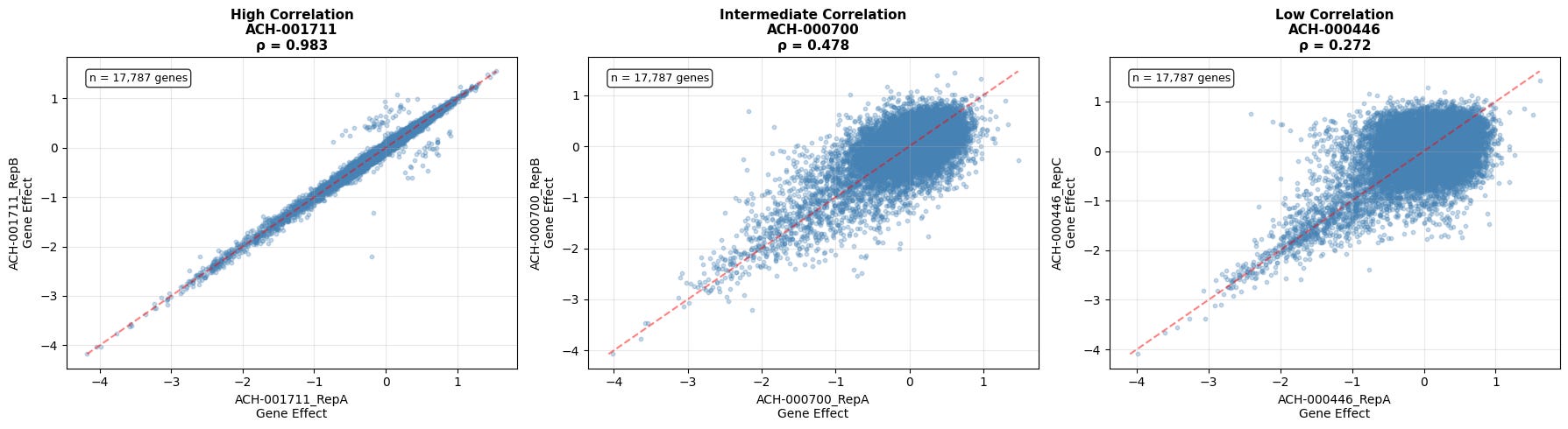
Even when replicate correlations are mediocre or low, strong gene effects stilly nicely hug the diagonal. That’s a clear and reproducible signal within the lab.
This is not the first time we’ve encountered this pattern: inter-lab reproducibility of interesting events being surprisingly low while their intra-lab reproducibility remains reasonably high.
What does this mean?
A tale of many truths
What if the original question is ill-defined?
If we ask, “What is the effect of a CRISPR knock-out of the gene EGFR in HCT-116 cells using the Avana library?”, we can already give a more precise answer.
Even more if: “What is the effect of a CRISPR knock-out of the gene EGFR in HCT-116 cells using the Avana library, with a 21-day transfection protocol, ….”
You can probably see where this is heading.
Reproducibility improves as we define the experiment better and better, but in doing that, we may be painting ourselves into a corner.
Every additional condition narrows the scope of the truth we are learning.
If all of these conditions are necessary to establish ground truth, then the knowledge we accumulate applies only within that very specific experimental setting.
This is not ideal.
Okay, if there is no single truth, can we at least say which data is better?
Better is what translates
Well, why are we doing any of this in the first place?
In this case, what we are trying to model are patients’ tumors with dysfunctional genes.
Of course, the slow accumulation of somatic mutations in a tumor is very different from the abrupt DNA damage introduced by CRISPR. But maybe, albeit imperfect, one protocol gives us a better model than the other.
So the quick answer is that the better data is the one that translates better.
But translation depends on the application
Can we now answer the original question?
Does Avana translate better than KY?
Well, translate where?
To patient tumors?
To neurodevelopmental processes?
To toxicity predictions?
If translation depends on the application, so must “better”.
Which probably means there is no single truth to learn from.
And if there is no single truth to learn from, there may never be a single experimental method that makes biology universally learnable. Such an understanding could emerge from a lot of different data sources and protocols somehow made to work together.
But what if nothing we can measure really translates?
Context transfer
The consensus is that CRISPR screens rarely translate as-is to patients1.
If that’s true, then - using this badly drawn image of biological surfaces and their measurement projections from the multimodality post -
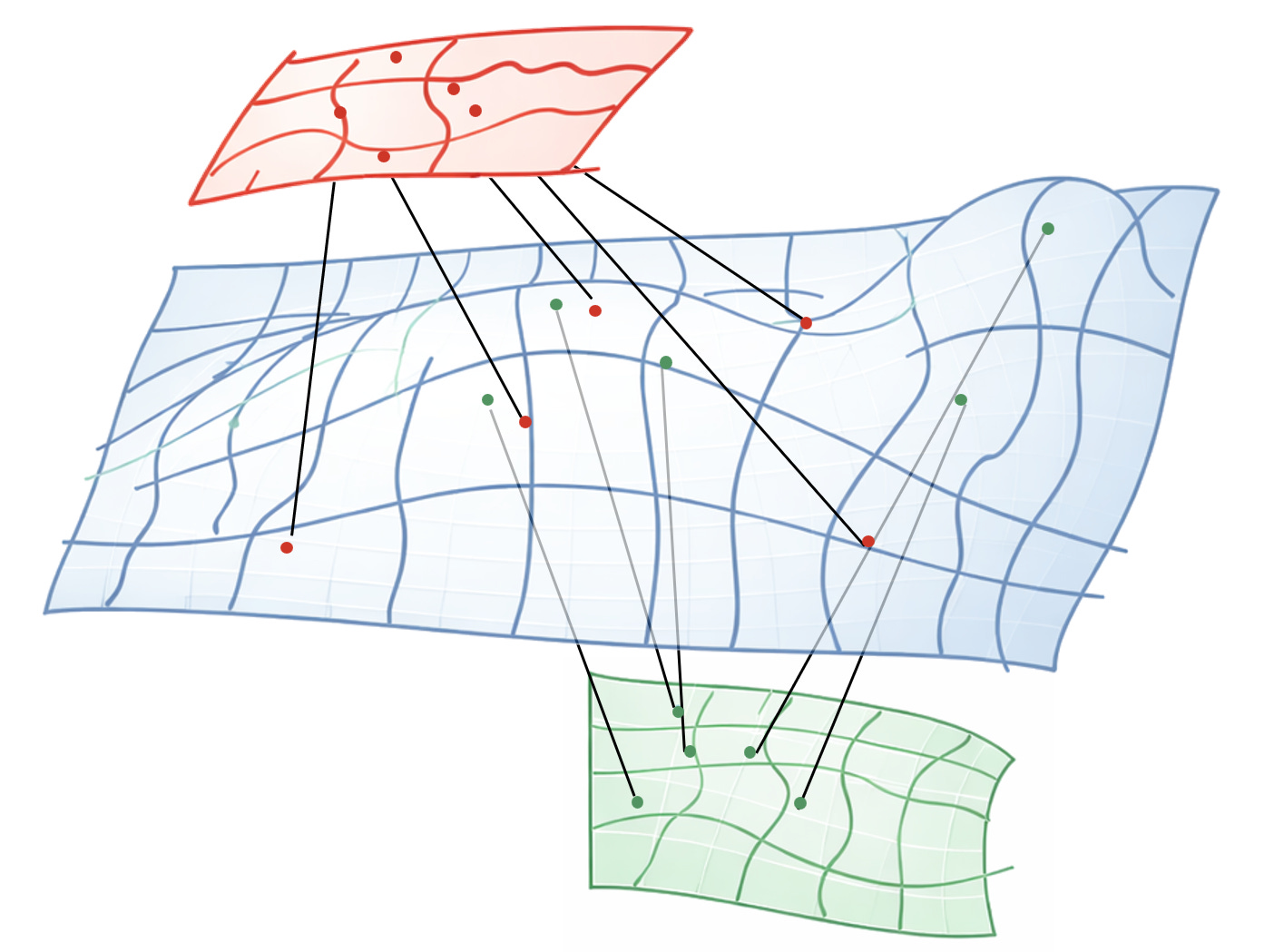
whatever you can measure in an in vitro CRISPR screen and whatever happens in the patient cancer microenvironment may not even be on overlapping slices of the blue space of cell states.
Which means that to create a general virtual cell, we cannot avoid starting to understand and map how the immeasurable blue surface behaves.
So, perhaps the goal is not to generate ever more data from a single protocol.
Perhaps the goal is to collect many different protocols and learn to translate among them.
Thanks to Miklos Laczik, Csaba Papp and Balazs Szabo for teaching us this with your investigation!
For example: “A systematic, genome-wide association analysis that
integrated CRISPR–Cas9 screens with pharmacological responses
for 397 drugs found clear associations between drug sensitivity and
the knockout of their canonical targets for only ~25% of the tested
compounds.” Gonçalves, E. et al. Drug mechanism-of-action discovery through the integration of pharmacological and CRISPR screens.